
The server deployment reading this week reframed something I had been thinking about mostly in terms of performance. I had assumed the primary challenges in edge computing deployment were latency and load balancing, but the article’s focus on robustness under abnormal conditions like soft attacks or sudden server failures added a dimension I hadn’t considered. Designing deployment strategies around failure modes rather than just optimal conditions feels like a more honest approach to real-world infrastructure. The concept of edge-delay-tolerant networks as a backup link mechanism was particularly interesting because it suggests that robustness isn’t just about redundancy, it’s about how quickly the system can reestablish connectivity when something breaks.
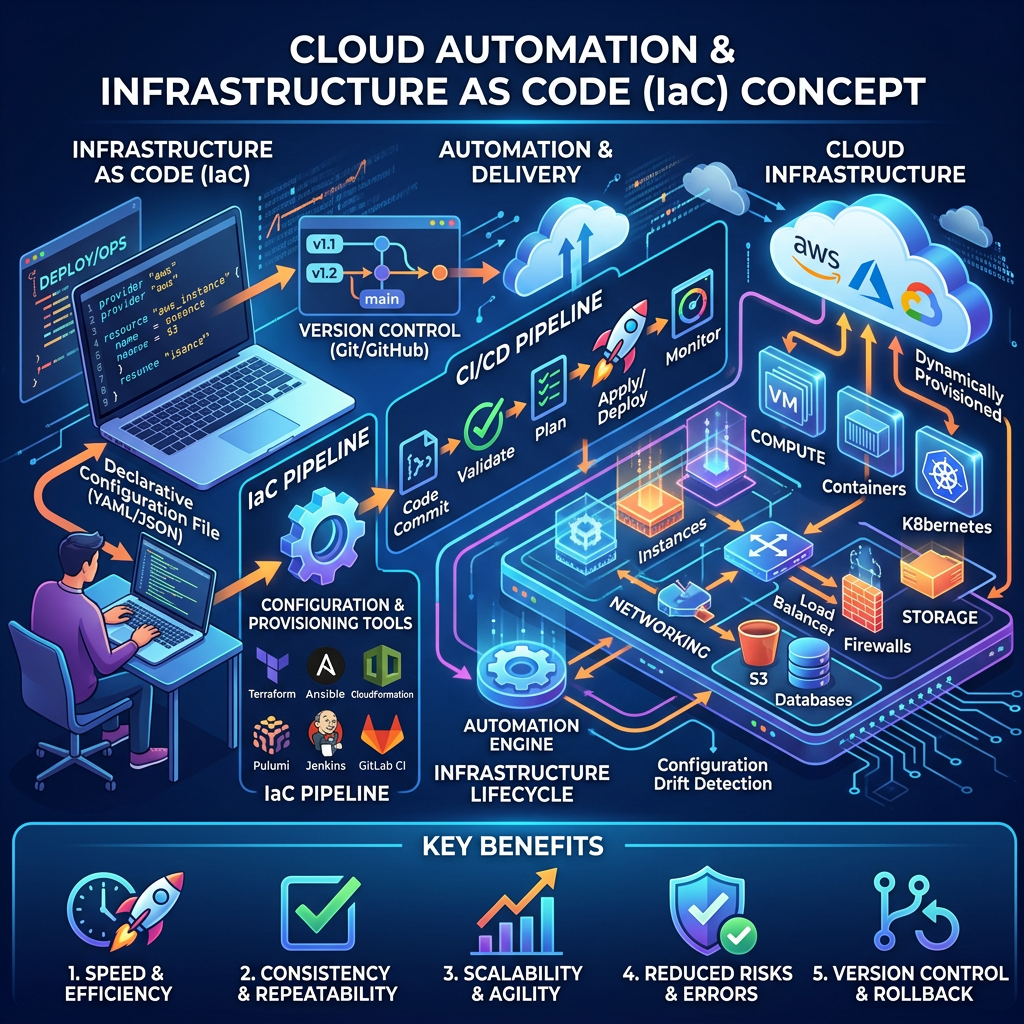
This connects directly to the VM allocation and containerized offloading material. In distributed edge environments, the assumption that resources will always be available starts to fall apart. Automation becomes less about convenience and more about survival, a system that can’t dynamically reallocate workloads in response to node failures isn’t really resilient, it’s just lucky.
The FedRAMP 20x news was genuinely surprising to me. The shift from document-heavy manual authorization to automation-driven, continuous compliance is a significant philosophical change. What stood out was the framing of compliance-as-code, embedding security controls directly into CI/CD pipelines so that authorization isn’t a one-time checkpoint but an ongoing, machine-readable state. The results so far are striking: authorization timelines that previously stretched over a year have been reduced to roughly five weeks. That’s not an incremental improvement; that’s a structural change in how security and deployment intersect.
Taken together, this week’s material pushed me to think about automation not just as an efficiency tool but as a prerequisite for operating reliably at scale, whether that’s managing edge servers under failure conditions or maintaining continuous security posture across a distributed cloud environment.

Leave a comment